Honorable Mention
M^2Lens: Visualizing and Explaining Multimodal Models for Sentiment Analysis
Xingbo Wang, Jianben He, Zhihua Jin, Muqiao Yang, Yong Wang, Huamin Qu
View presentation:2021-10-27T13:45:00ZGMT-0600Change your timezone on the schedule page
2021-10-27T13:45:00Z
Fast forward
Direct link to video on YouTube: https://youtu.be/AGpbSwRnhaQ
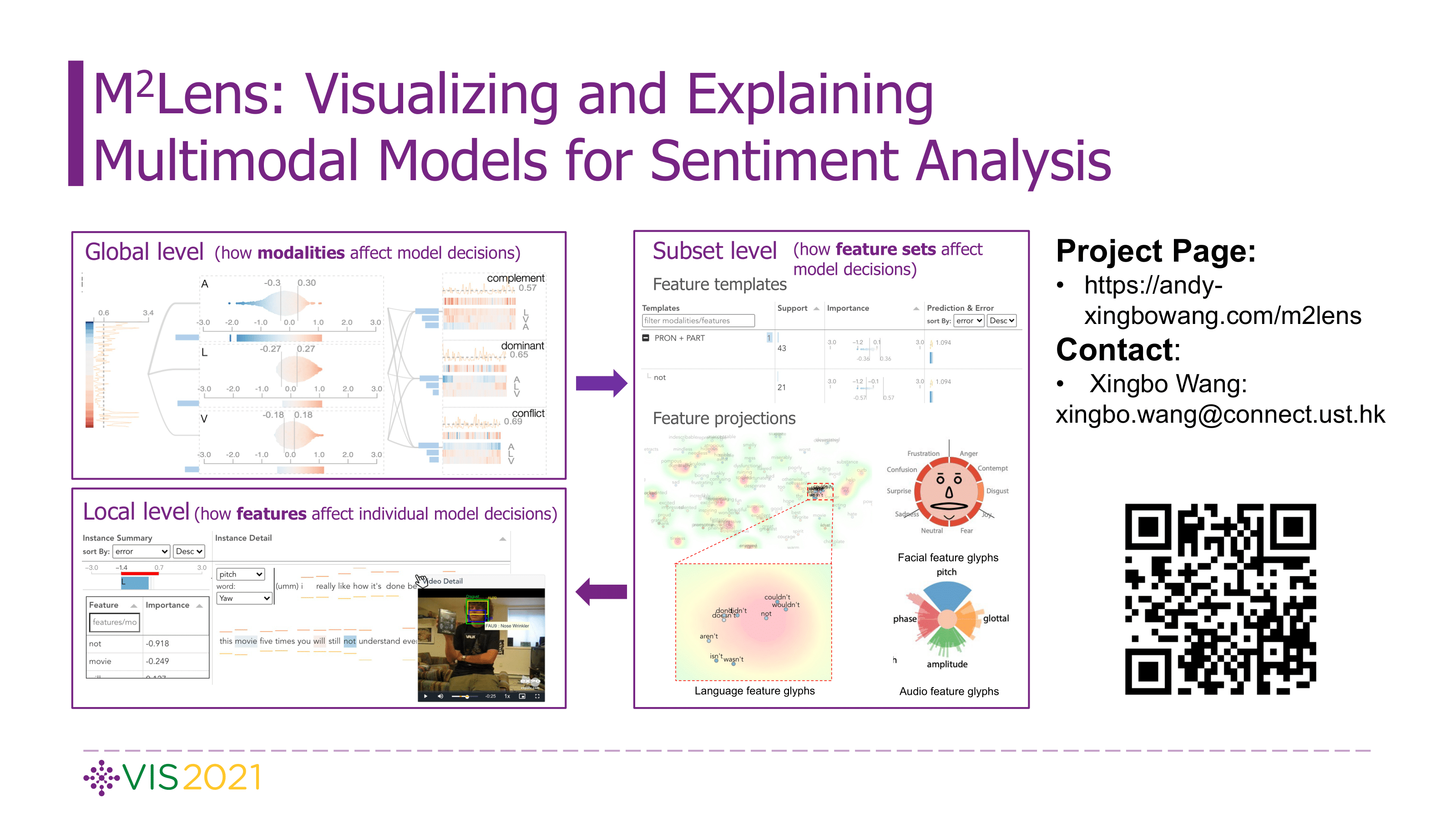
Abstract
Multimodal sentiment analysis aims to recognize people’s attitudes from multiple communication channels such as verbal content (i.e., text), voice, and facial expressions. It has become a vibrant and important research topic in natural language processing. Much research focuses on modeling the complex intra- and inter-modal interactions between different communication channels. However, current multimodal models with strong performance are often deep-learning-based techniques and work like black boxes. It is not clear how models utilize multimodal information for sentiment predictions. Despite recent advances in techniques for enhancing the explainability of machine learning models, they often target unimodal scenarios (e.g., images, sentences), and little research has been done on explaining multimodal models. In this paper, we present an interactive visual analytics system, M2Lens, to visualize and explain multimodal models for sentiment analysis. M2Lens provides explanations on intra- and inter-modal interactions at the global, subset, and local levels. Specifically, it summarizes the influence of three typical interaction types (i.e., dominance, complement, and conflict) on the model predictions. Moreover, M2Lens identifies frequent and influential multimodal features and supports the multi-faceted exploration of model behaviors from language, acoustic, and visual modalities. Through two case studies and expert interviews, we demonstrate our system can help users gain deep insights into the multimodal models for sentiment analysis.