Honorable Mention
An Evaluation-Focused Framework for Visualization Recommendation Algorithms
Zehua Zeng, Phoebe Moh, Fan Du, Jane Hoffswell, Tak Yeon Lee, Sana Malik, Eunyee Koh, Leilani Battle
External link (DOI)
View presentation:2021-10-29T15:15:00ZGMT-0600Change your timezone on the schedule page
2021-10-29T15:15:00Z
Abstract
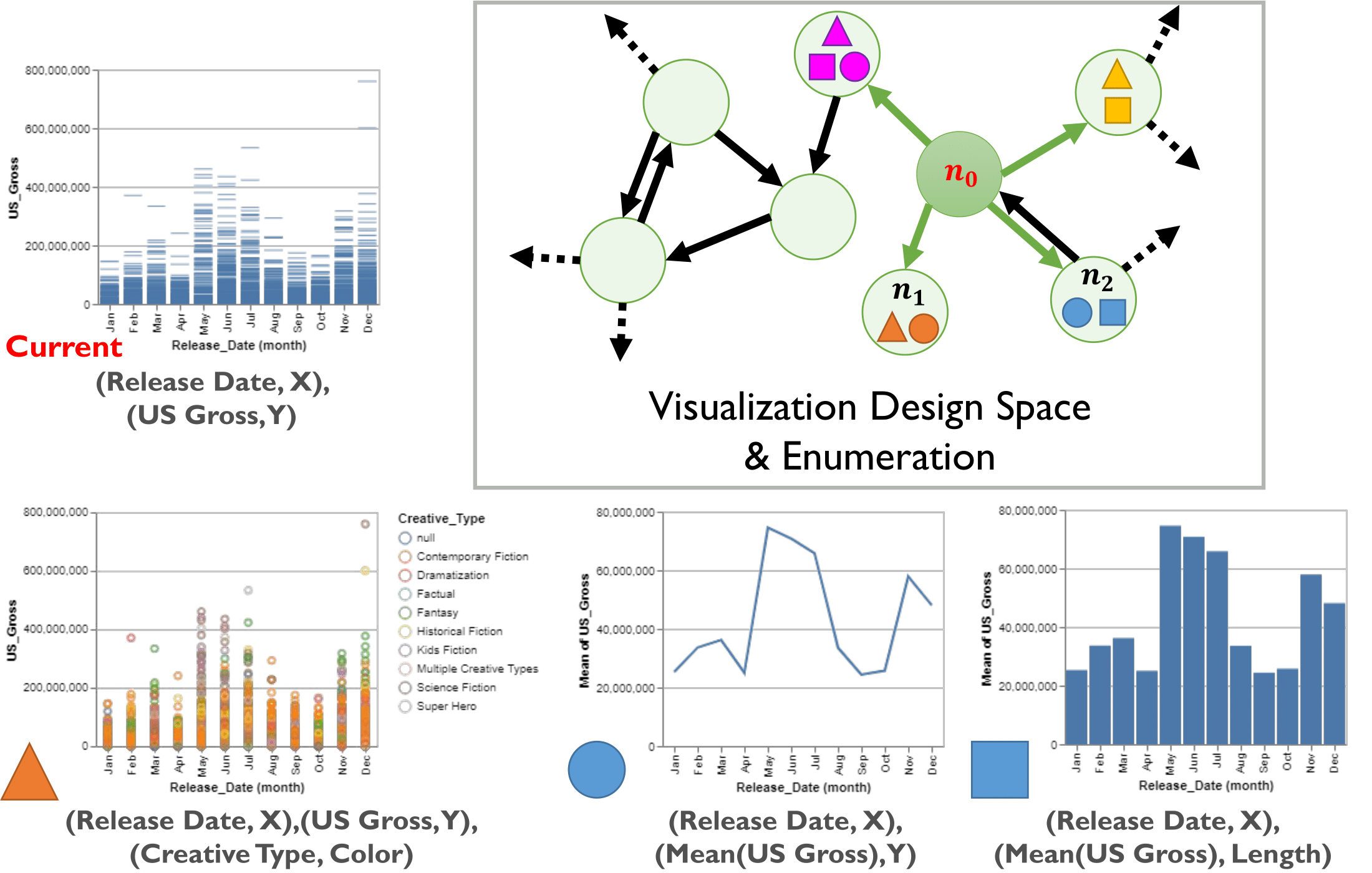
Although we have seen a proliferation of algorithms for recommending visualizations, these algorithms are rarely compared with one another, making it difficult to ascertain which algorithm is best for a given visual analysis scenario. Though several formal frameworks have been proposed in response, we believe this issue persists because visualization recommendation algorithms are inadequately specified from an evaluation perspective. In this paper, we propose an evaluation-focused framework to contextualize and compare a broad range of visualization recommendation algorithms. We present the structure of our framework, where algorithms are specified using three components: (1) a graph representing the full space of possible visualization designs, (2) the method used to traverse the graph for potential candidates for recommendation, and (3) an oracle used to rank candidate designs. To demonstrate how our framework guides the formal comparison of algorithmic performance, we not only theoretically compare five existing representative recommendation algorithms, but also empirically compare four new algorithms generated based on our findings from the theoretical comparison. Our results show that these algorithms behave similarly in terms of user performance, highlighting the need for more rigorous formal comparisons of recommendation algorithms to further clarify their benefits in various analysis scenarios.