Best Paper Award
Simultaneous Matrix Orderings for Graph Collections
Nathan van Beusekom, Wouter Meulemans, Bettina Speckmann
External link (DOI)
View presentation:2021-10-26T15:00:00ZGMT-0600Change your timezone on the schedule page
2021-10-26T15:00:00Z
Fast forward
Direct link to video on YouTube: https://youtu.be/0BIMBxNBSgk
Abstract
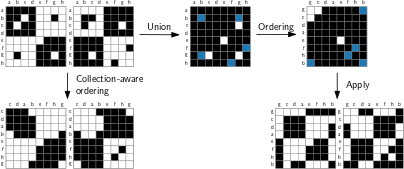
Undirected graphs are frequently used to model phenomena that deal with interacting objects, such as social networks, brain activity and communication networks. The topology of an undirected graph G can be captured by an adjacency matrix; this matrix in turn can be visualized directly to give insight into the graph structure. Which visual patterns appear in such a matrix visualization crucially depends on the ordering of its rows and columns. Formally defining the quality of an ordering and then automatically computing a high-quality ordering are both challenging problems; however, effective heuristics exist and are used in practice. Often, graphs do not exist in isolation but as part of a collection of graphs on the same set of vertices, for example, brain scans over time or of different people. To visualize such graph collections, we need a single ordering that works well for all matrices simultaneously. The current state-of-the-art solves this problem by taking a (weighted) union over all graphs and applying existing heuristics. However, this union leads to a loss of information, specifically in those parts of the graphs which are different. We propose a collection-aware approach to avoid this loss of information and apply it to two popular heuristic methods: leaf order and barycenter. The de-facto standard computational quality metrics for matrix ordering capture only block-diagonal patterns (cliques). Instead, we propose to use Moran's I, a spatial auto-correlation metric, which captures the full range of established patterns. Moran's I refines previously proposed stress measures. Furthermore, the popular leaf order method heuristically optimizes a similar measure which further supports the use of Moran's I in this context. An ordering that maximizes Moran's I can be computed via solutions to the Traveling Salesperson Problem (TSP); approximate orderings can be computed more efficiently, using any of the approximation algorithms for metric TSP. We evaluated our methods for simultaneous orderings on real-world datasets using Moran's I as the quality metric. Our results show that our collection-aware approach matches or improves performance compared to the union approach, depending on the similarity of the graphs in the collection. Specifically, our Moran's I-based collection-aware leaf order implementation consistently outperforms other implementations. Our collection-aware implementations carry no significant additional computational costs.