Human-in-the-loop Extraction of Interpretable Concepts in Deep Learning Models
Zhenge Zhao, Panpan Xu, Carlos Scheidegger, Liu Ren
External link (DOI)
View presentation:2021-10-27T13:15:00ZGMT-0600Change your timezone on the schedule page
2021-10-27T13:15:00Z
Fast forward
Direct link to video on YouTube: https://youtu.be/OrnFfB7rCKY
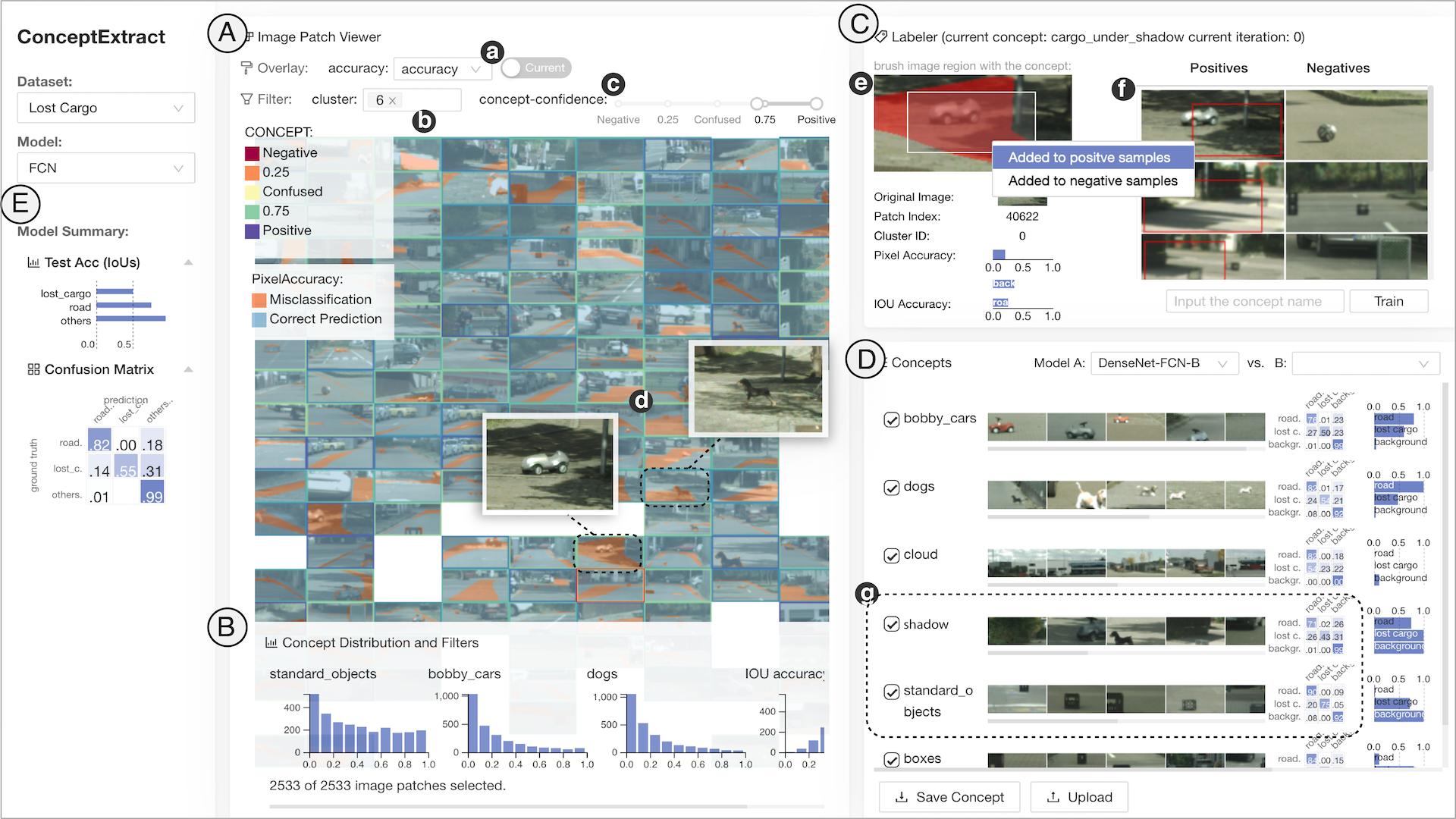
Abstract
The interpretation of deep neural networks (DNNs) has become a key topic as more people apply them to solve various problems and making critical decisions. Recently, concept-based explanation has become a popular approach for post-hoc interpretation of DNNs. Instead of focusing on a single data sample to obtain local interpretation such as saliency maps, concept-based explanation provides a global interpretation of model predictions by analyzing how visual concepts affects model decision. For example, how the presence of shadow affects an object detection model. However, identifying human-friendly visual concepts that affect model decisions is a challenging task that can not be easily addressed with automatic approaches. In this paper, we present a novel human-in-the-loop visual analytics framework to generate user-defined concepts for model interpretation and diagnostics. The core of our approach is the use of active learning, where we integrate human knowledge and feedback to train a concept extractor in each stage. We crop or segment the original images into small image patches, extract the latent presentations from the hidden layer of the task model, select image patches sharing a common concept, and train a shallow net on top of the latent representation to collect image patches containing the visual concept. We combine these processes into an interactive system, ConceptExtract. Through two case studies, we show how our approach helps analyze model behavior and extract human-friendly concepts for different machine learning tasks and datasets and how to use these concepts to understand the predictions, compare model performance and make suggestions for model refinement. Quantitative experiments show that our active learning approach can accurately extract meaningful visual concepts. More importantly, by identifying visual concepts that negatively affect model performance, we develop the corresponding data augmentation strategy that consistently improves model performance.