VisCode: Embedding Information in Visualization Images using Encoder-Decoder Network
Peiying Zhang, Chenhui Li, Changbo Wang
External link (DOI)
View presentation:2020-10-27T18:45:00ZGMT-0600Change your timezone on the schedule page
2020-10-27T18:45:00Z
Keywords
Image and Video Data, Algorithms, Application Motivated Visualization, Other Application Areas, Perception & Cognition, Image and Signal Processing
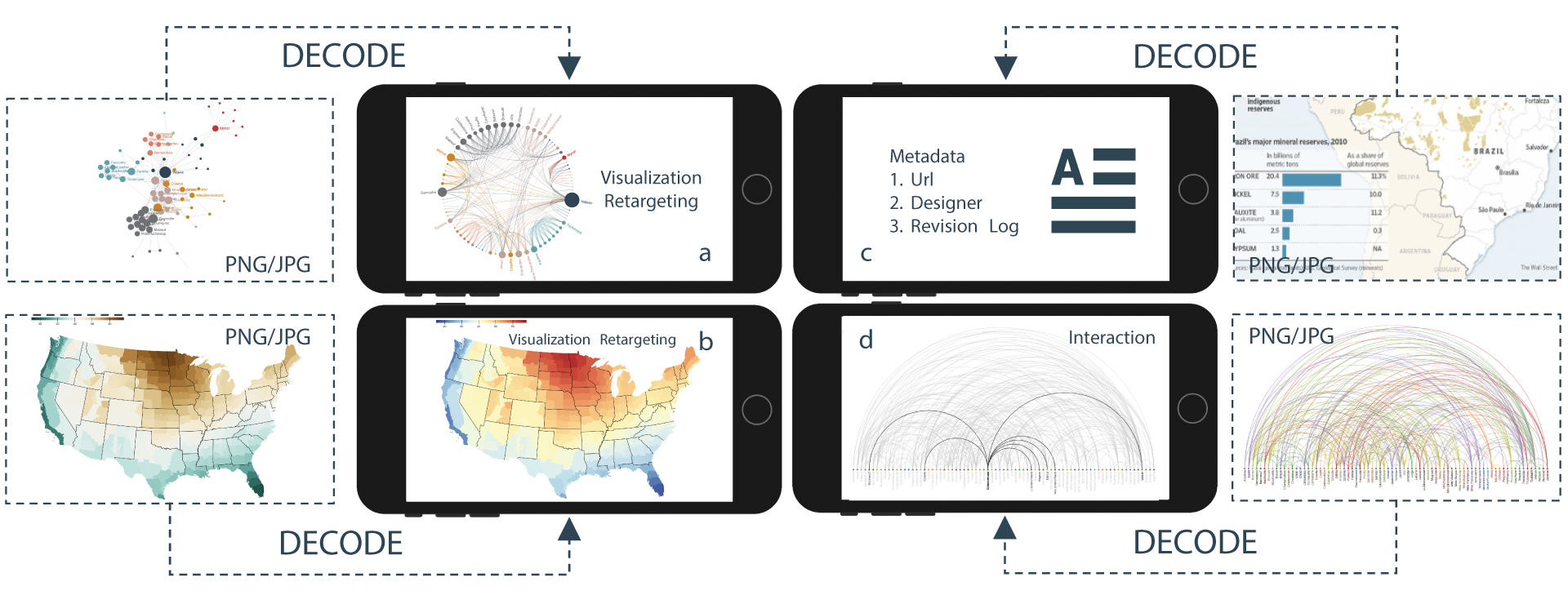
Abstract
We present an approach called VisCode for embedding information into visualization images. This technology can implicitly embed data information specified by the user into a visualization while ensuring that the encoded visualization image is not distorted. The VisCode framework is based on a deep neural network. We propose to use visualization images and QR codes data as training data and design a robust deep encoder-decoder network. The designed model considers the salient features of visualization images to reduce the explicit visual loss caused by encoding. To further support large-scale encoding and decoding, we consider the characteristics of information visualization and propose a saliency-based QR code layout algorithm. We present a variety of practical applications of VisCode in the context of information visualization and conduct a comprehensive evaluation of the perceptual quality of encoding, decoding success rate, anti-attack capability, time performance, etc. The evaluation results demonstrate the effectiveness of VisCode.