Adaptively Placed Multi-Grid Scene Representation Networks for Large-Scale Data Visualization
Skylar Wolfgang Wurster, Tianyu Xiong, Han-Wei Shen, Hanqi Guo, Tom Peterka
DOI: 10.1109/TVCG.2023.3327194
Room: 106
2023-10-26T00:21:00ZGMT-0600Change your timezone on the schedule page
2023-10-26T00:21:00Z
Fast forward
Full Video
Keywords
Scene representation network, deep learning, scientific visualization, volume rendering
Abstract
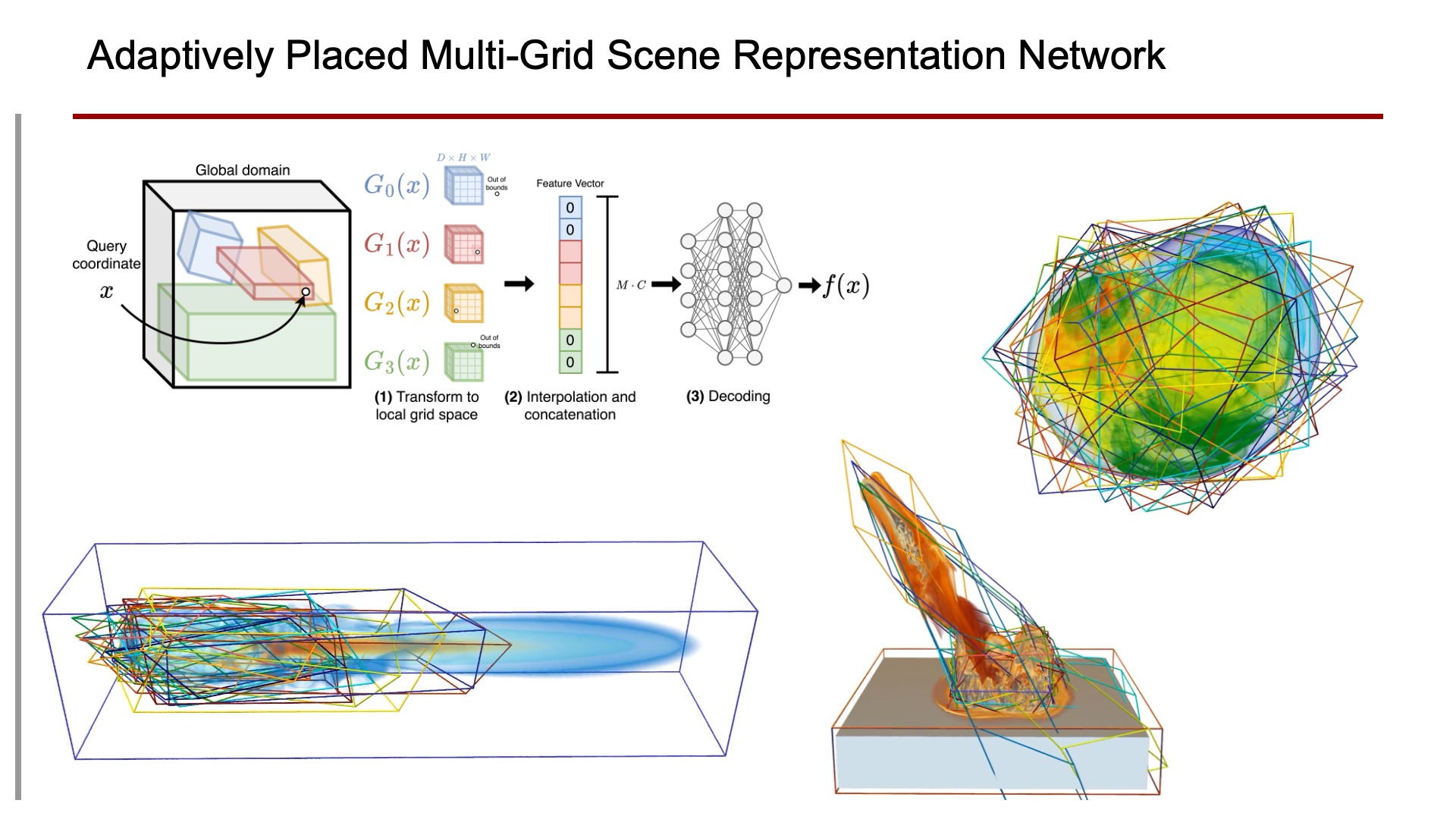
Scene representation networks (SRNs) have been recently proposed for compression and visualization of scientific data. However, state-of-the-art SRNs do not adapt the allocation of available network parameters to the complex features found in scientific data, leading to a loss in reconstruction quality. We address this shortcoming with an adaptively placed multi-grid SRN (APMGSRN) and propose a domain decomposition training and inference technique for accelerated parallel training on multi-GPU systems. We also release an open-source neural volume rendering application that allows plug-and-play rendering with any PyTorch-based SRN. Our proposed APMGSRN architecture uses multiple spatially adaptive feature grids that learn where to be placed within the domain to dynamically allocate more neural network resources where error is high in the volume, improving state-of-the-art reconstruction accuracy of SRNs for scientific data without requiring expensive octree refining, pruning, and traversal like previous adaptive models. In our domain decomposition approach for representing large-scale data, we train an set of APMGSRNs in parallel on separate bricks of the volume to reduce training time while avoiding overhead necessary for an out-of-core solution for volumes too large to fit in GPU memory. After training, the lightweight SRNs are used for realtime neural volume rendering in our open-source renderer, where arbitrary view angles and transfer functions can be explored. A copy of this paper, all code, all models used in our experiments, and all supplemental materials and videos are available at https://github.com/skywolf829/APMGSRN.