CommonsenseVIS: Visualizing and Understanding Commonsense Reasoning Capabilities of Natural Language Models
Xingbo Wang, Renfei Huang, Zhihua Jin, Tianqing Fang, Huamin Qu
DOI: 10.1109/TVCG.2023.3327153
Room: 106
2023-10-25T00:21:00ZGMT-0600Change your timezone on the schedule page
2023-10-25T00:21:00Z
Fast forward
Full Video
Keywords
Commonsense reasoning, visual analytics, XAI, natural language processing
Abstract
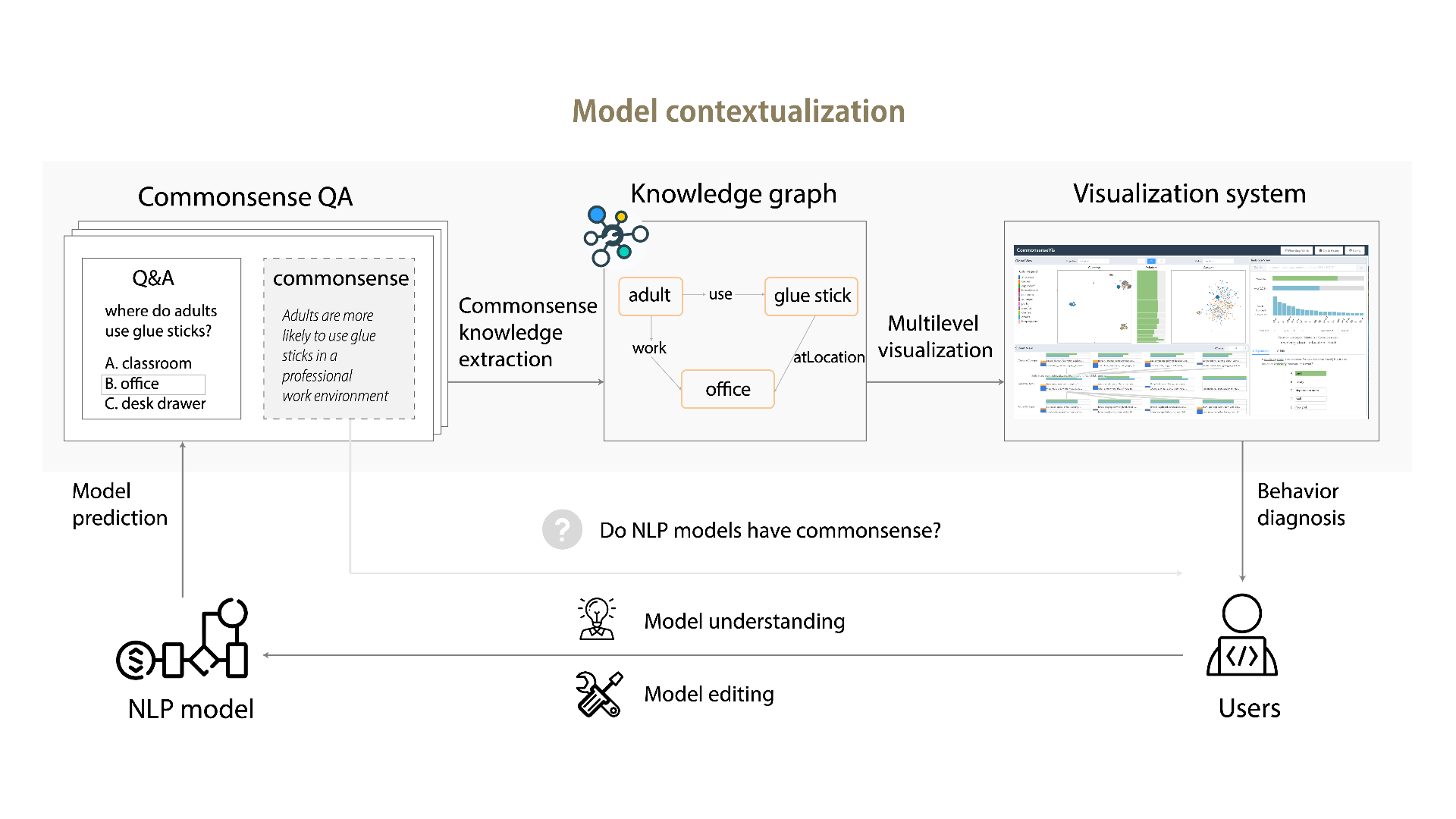
Recently, large pretrained language models have achieved compelling performance on commonsense benchmarks. Nevertheless, it is unclear what commonsense knowledge the models learn and whether they solely exploit spurious patterns. Feature attributions are popular explainability techniques that identify important input concepts for model outputs. However, commonsense knowledge tends to be implicit and rarely explicitly presented in inputs. These methods cannot infer models’ implicit reasoning over mentioned concepts. We present CommonsenseVIS, a visual explanatory system that utilizes external commonsense knowledge bases to contextualize model behavior for commonsense question-answering. Specifically, we extract relevant commonsense knowledge in inputs as references to align model behavior with human knowledge. Our system features multi-level visualization and interactive model probing and editing for different concepts and their underlying relations. Through a user study, we show that CommonsenseVIS helps NLP experts conduct a systematic and scalable visual analysis of models’ relational reasoning over concepts in different situations.