A Task-Parallel Approach for Localized Topological Data Structures
Guoxi Liu, Federico Iuricich
DOI: 10.1109/TVCG.2023.3327182
Room: 106
2023-10-26T05:09:00ZGMT-0600Change your timezone on the schedule page
2023-10-26T05:09:00Z
Fast forward
Full Video
Keywords
Data structures, parallel computation, topological data analysis, simplicial complex
Abstract
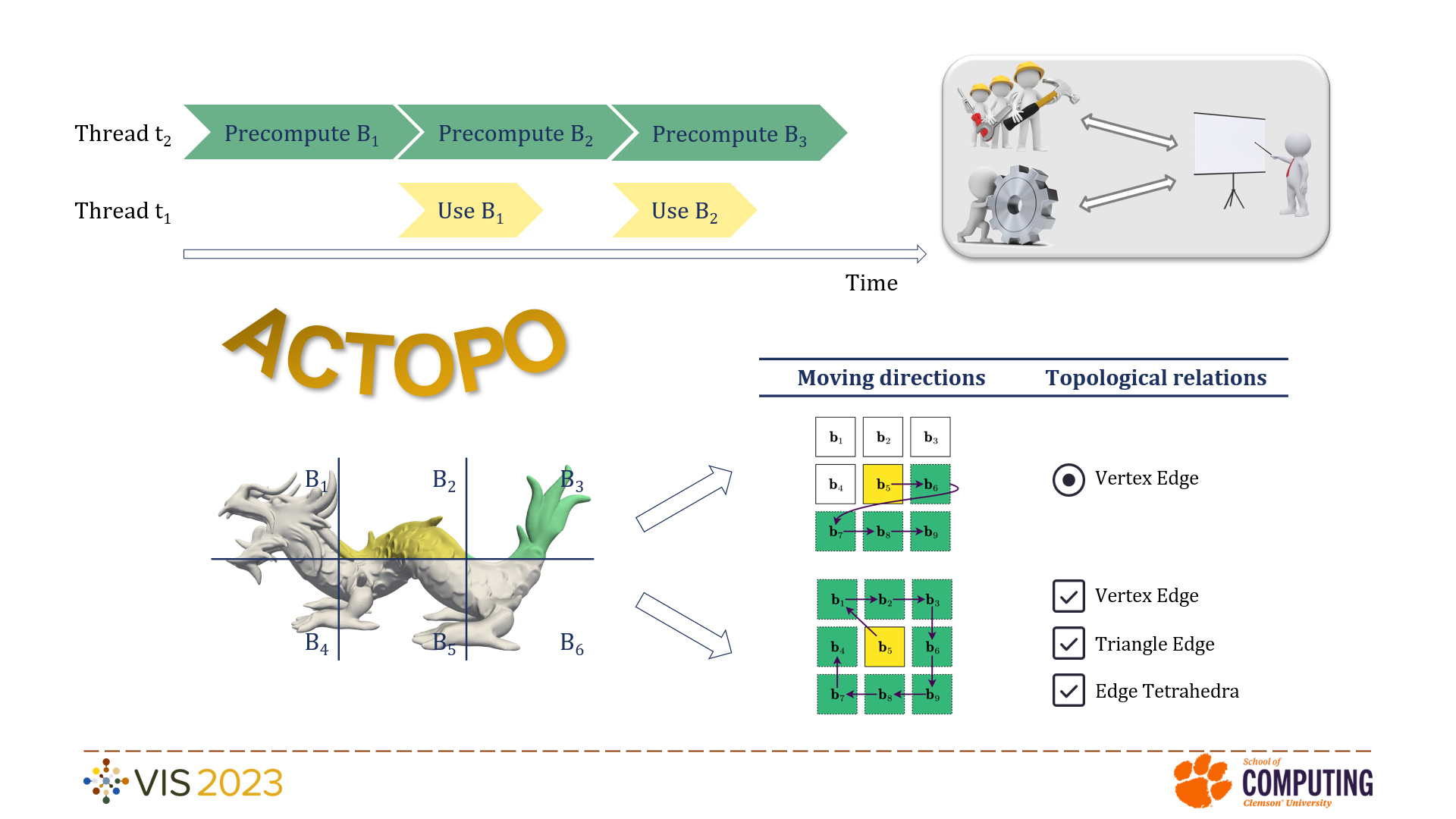
Unstructured meshes are characterized by data points irregularly distributed in the Euclidian space. Due to the irregular nature of these data, computing connectivity information between the mesh elements requires much more time and memory than on uniformly distributed data. To lower storage costs, dynamic data structures have been proposed. These data structures compute connectivity information on the fly and discard them when no longer needed. However, on-the-fly computation slows down algorithms and results in a negative impact on the time performance. To address this issue, we propose a new task-parallel approach to proactively compute mesh connectivity. Unlike previous approaches implementing data-parallel models, where all threads run the same type of instructions, our task-parallel approach allows threads to run different functions. Specifically, some threads run the algorithm of choice while other threads compute connectivity information before they are actually needed. The approach was implemented in the new Accelerated Clustered TOPOlogical (ACTOPO) data structure, which can support any processing algorithm requiring mesh connectivity information. Our experiments show that ACTOPO combines the benefits of state-of-the-art memory-efficient (TTK CompactTriangulation) and time-efficient (TTK ExplicitTriangulation) topological data structures. It occupies a similar amount of memory as TTK CompactTriangulation while providing up to 5x speedup. Moreover, it achieves comparable time performance as TTK ExplicitTriangulation while using only half of the memory space.