Visualizing Linguistic Diversity of Text Datasets Synthesized by Large Language Models
Emily Reif, Minsuk Kahng, Savvas Petridis
Room: 104
2023-10-26T22:36:00ZGMT-0600Change your timezone on the schedule page
2023-10-26T22:36:00Z
Fast forward
Full Video
Keywords
Visualization—Text—MLStatsModel
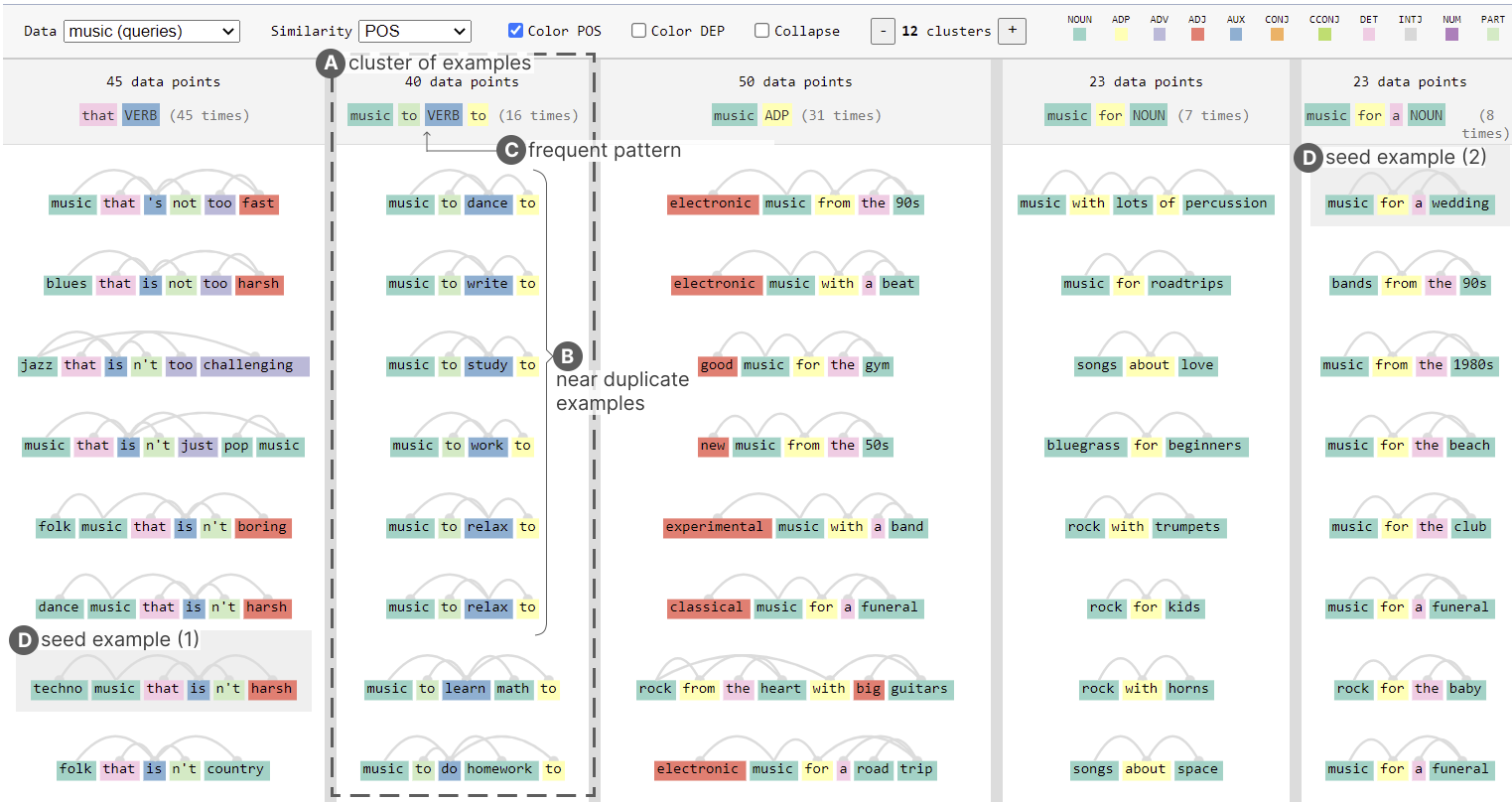
Abstract
Large language models (LLMs) can be used to generate smaller, more refined datasets via few-shot prompting for benchmarking, fine-tuning or other use cases. However, understanding and evaluating these datasets is difficult, and the failure modes of LLM-generated data are still not well understood. Specifically, the data can be repetitive in surprising ways, not only semantically but also syntactically and lexically. We present LinguisticLens, a novel interactive visualization tool for making sense of and analyzing syntactic diversity of LLM-generated datasets. LinguisticLens clusters text along syntactic, lexical, and semantic axes. It supports hierarchical visualization of a text dataset, allowing users to quickly scan for an overview and inspect individual examples. The live demo is available at https://shorturl.at/zHOUV.