WEC-Explainer: A Descriptive Framework for Exploring Word Embedding Contextualization
Rita Sevastjanova, Mennatallah El-Assady
Room: 110
2023-10-22T03:00:00ZGMT-0600Change your timezone on the schedule page
2023-10-22T03:00:00Z
Fast forward
Abstract
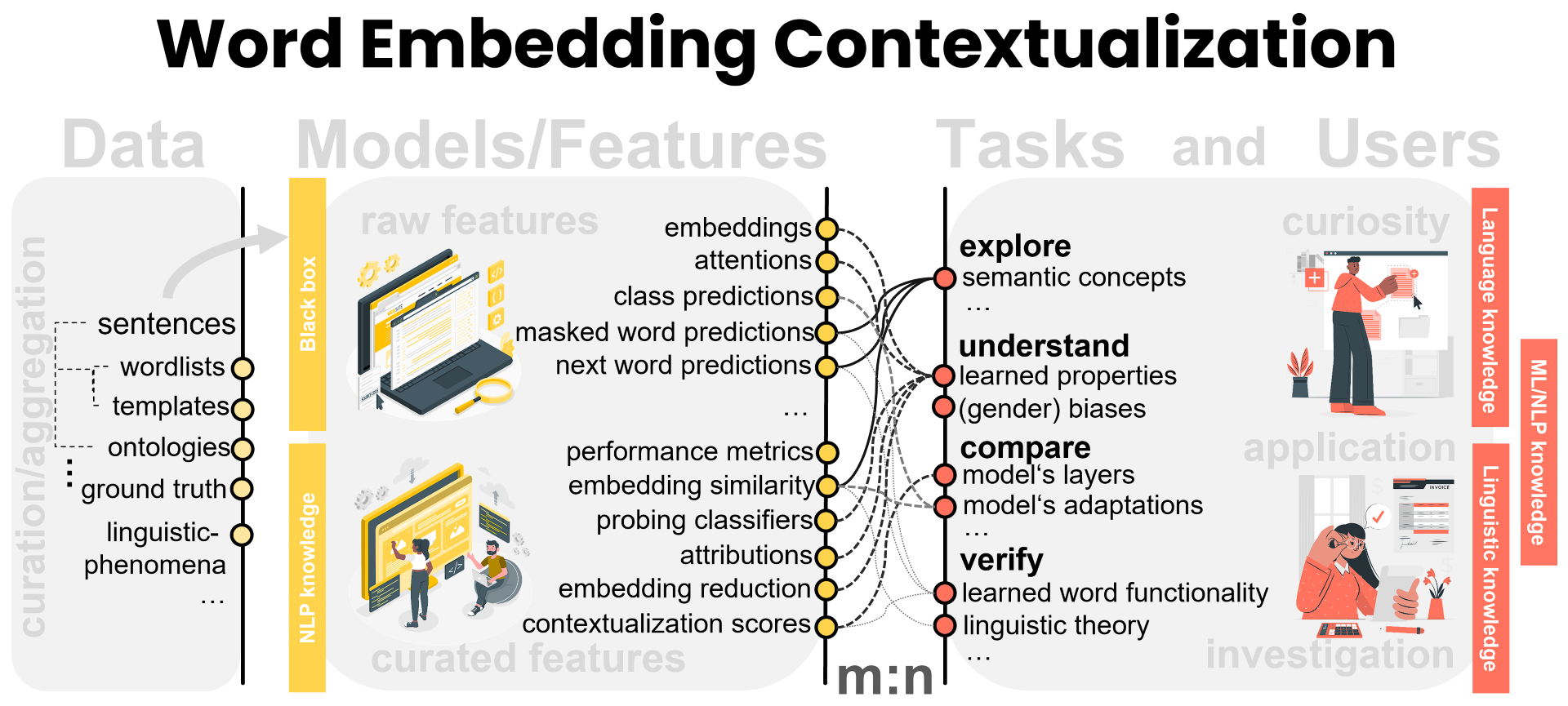
Contextual word embeddings -- high-dimensional vectors that encode the semantic similarity between words -- are proven to be effective for diverse natural language processing applications. These embeddings originate in large language models and are updated throughout the model's architecture (i.e., the model's layers). Given their intricacy, the explanation of embedding characteristics and limitations -- their contextualization -- has emerged as a widely investigated research subject. To provide an overview of the existing explanation methods and motivate researchers to design new approaches, we present a descriptive framework that connects data, features, tasks, and users involved in the word embedding explanation process. We use the framework as theoretical groundwork and implement a data processing pipeline that we use to solve three different tasks related to word embedding contextualization. These tasks enable answering questions about the encoded context properties in the embedding vectors, captured semantic concepts and their similarity, and masked-prediction meaningfulness and their relation to embedding characteristics. We show that divergent research questions can be analyzed by combining different data curation methods with a similar set of features.