High-Quality Progressive Alignment of Large 3D Microscopy Data
Aniketh Venkat
View presentation:2022-10-16T16:35:00ZGMT-0600Change your timezone on the schedule page
2022-10-16T16:35:00Z
The live footage of the talk, including the Q&A, can be viewed on the session page, LDAV: Parallelization & Progressiveness.
Abstract
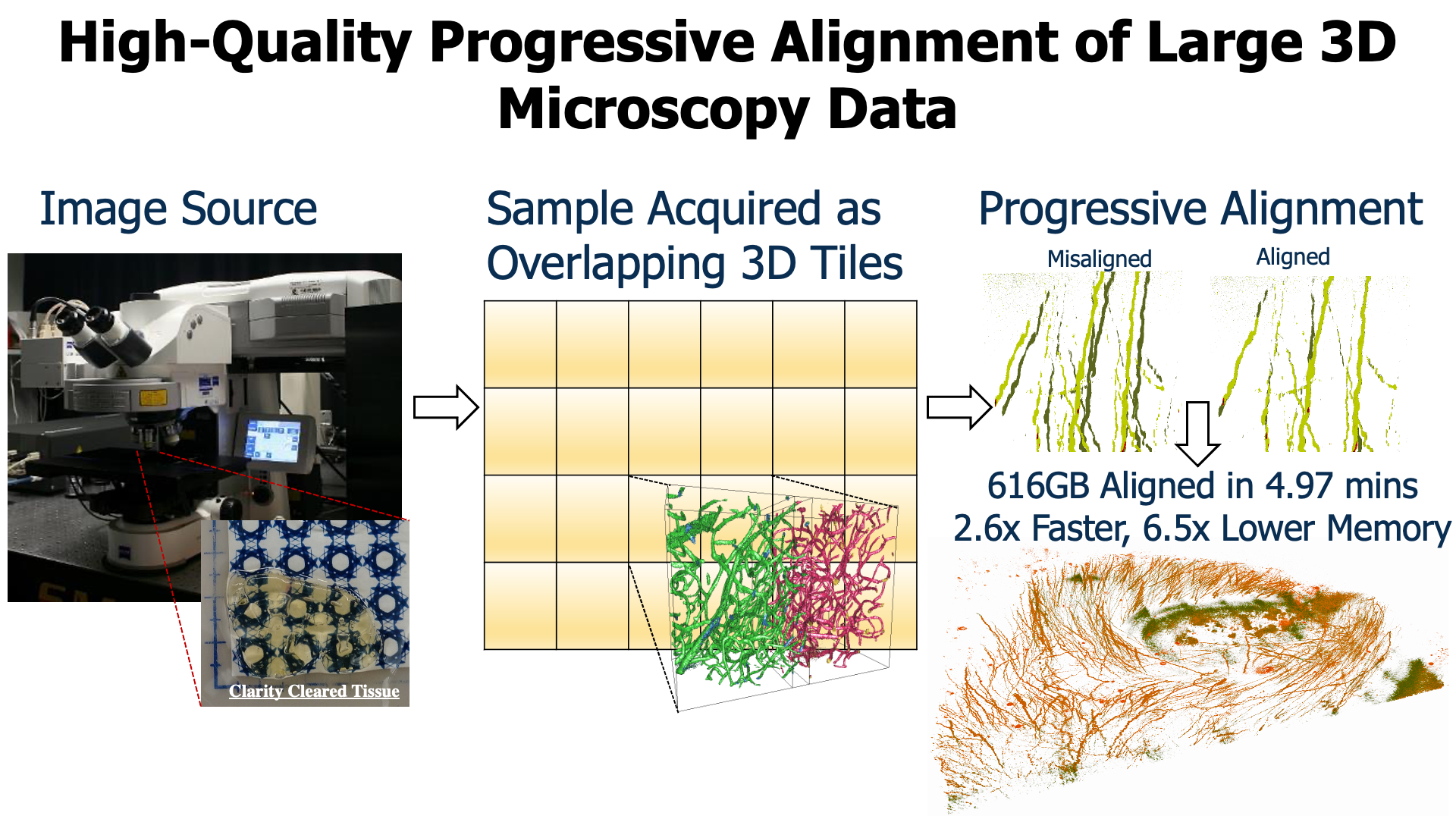
Large-scale three-dimensional (3D) microscopy acquisitions frequently create terabytes of image data at high resolution and magnification. Imaging large specimens at high magnifications requires acquiring 3D overlapping image stacks as tiles arranged on a two-dimensional (2D) grid that must subsequently be aligned and fused into a single 3D volume. Due to their sheer size, aligning many overlapping gigabyte-sized 3D tiles in parallel and at full resolution is memory intensive and often I/O bound. Current techniques trade accuracy for scalability, perform alignment on subsampled images, and require additional postprocess algorithms to refine the alignment quality, usually with high computational requirements. One common solution to the memory problem is to subdivide the overlap region into smaller chunks (sub-blocks) and align the sub-block pairs in parallel, choosing the pair with the most reliable alignment to determine the global transformation. Yet aligning all sub-block pairs at full resolution remains computationally expensive. The key to quickly developing a fast, high-quality, low-memory solution is to identify a single or a small set of sub-blocks that give good alignment at full resolution without touching all the overlapping data. In this paper, we present a new iterative approach that leverages coarse resolution alignments to progressively refine and align only the promising candidates at finer resolutions, thereby aligning only a small user-defined number of sub-blocks at full resolution to determine the lowest error transformation between pairwise overlapping tiles. Our progressive approach is 2.6x faster than the state of the art, requires less than 450MB of peak RAM (per parallel thread), and offers a higher quality alignment without the need for additional postprocessing refinement steps to correct for alignment errors.