Visual Comparison of Language Model Adaptation
Rita Sevastjanova, Eren Cakmak, Shauli Ravfogel, Ryan Cotterell, Mennatallah El-Assady
View presentation:2022-10-21T15:00:00ZGMT-0600Change your timezone on the schedule page
2022-10-21T15:00:00Z
Prerecorded Talk
The live footage of the talk, including the Q&A, can be viewed on the session page, Comparisons.
Fast forward
Abstract
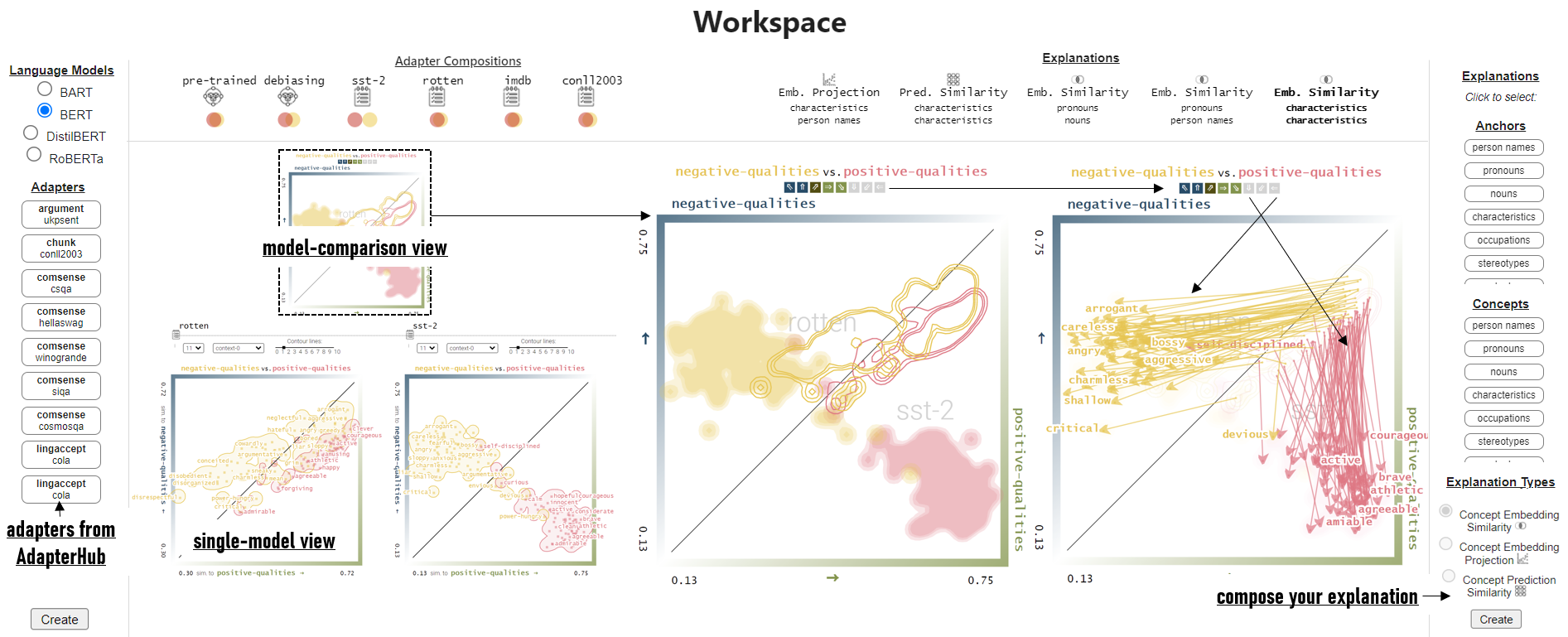
Neural language models are widely used; however, their model parameters often need to be adapted to the specific domains and tasks of an application, which is time- and resource-consuming. Thus, adapters have recently been introduced as a lightweight alternative for model adaptation. They consist of a small set of task-specific parameters with a reduced training time and simple parameter composition. The simplicity of adapter training and composition comes along with new challenges, such as maintaining an overview of adapter properties and effectively comparing their produced embedding spaces. To help developers overcome these challenges, we provide a twofold contribution. First, in close collaboration with NLP researchers, we conducted a requirement analysis for an approach supporting adapter evaluation and detected, among others, the need for both intrinsic (i.e., embedding similarity-based) and extrinsic (i.e., prediction-based) explanation methods. Second, motivated by the gathered requirements, we designed a flexible visual analytics workspace that enables the comparison of adapter properties. In this paper, we discuss several design iterations and alternatives for interactive, comparative visual explanation methods. Our comparative visualizations show the differences in the adapted embedding vectors and prediction outcomes for diverse human-interpretable concepts (e.g., person names, human qualities). We evaluate our workspace through case studies and show that, for instance, an adapter trained on the language debiasing task according to context-0 (decontextualized) embeddings introduces a new type of bias where words (even gender-independent words such as countries) become more similar to female- than male pronouns. We demonstrate that these are artifacts of context-0 embeddings, and the adapter effectively eliminates the gender information from the contextualized word representations.