VDL-Surrogate: A View-Dependent Latent-based Model for Parameter Space Exploration of Ensemble Simulations
Neng Shi, Jiayi Xu, Haoyu Li, Hanqi Guo, Jonathan Woodring, Han-Wei Shen
View presentation:2022-10-20T15:57:00ZGMT-0600Change your timezone on the schedule page
2022-10-20T15:57:00Z
Prerecorded Talk
The live footage of the talk, including the Q&A, can be viewed on the session page, Interpreting Machine Learning.
Fast forward
Abstract
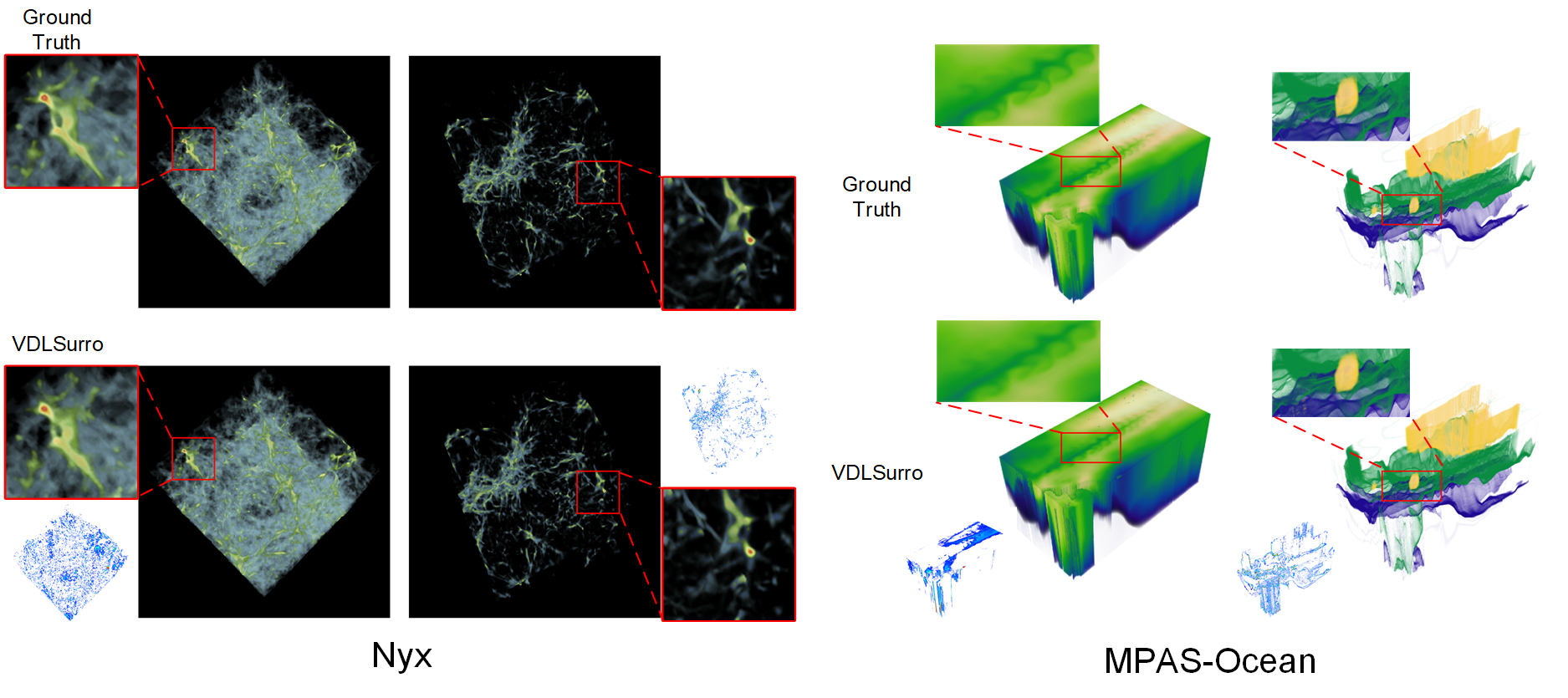
We propose VDL-Surrogate, a view-dependent neural-network-latent-based surrogate model for parameter space exploration of ensemble simulations that allows high-resolution visualizations and user-specified visual mappings. Surrogate-enabled parameter space exploration allows domain scientists to preview simulation results without having to run a large number of computationally costly simulations. Limited by computational resources, however, existing surrogate models may not produce previews with sufficient resolution for visualization and analysis. To improve the efficient use of computational resources and support high-resolution exploration, we perform ray casting from different viewpoints to collect samples and produce compact latent representations. This latent encoding process reduces the cost of surrogate model training while maintaining the output quality. In the model training stage, we select viewpoints to cover the whole viewing sphere and train corresponding VDL-Surrogate models for the selected viewpoints. In the model inference stage, we predict the latent representations at previously selected viewpoints and decode the latent representations to data space. For any given viewpoint, we make interpolations over decoded data at selected viewpoints and generate visualizations with user-specified visual mappings. We show the effectiveness and efficiency of VDL-Surrogate in cosmological and ocean simulations with quantitative and qualitative evaluations. Source code is publicly available at \url{https://github.com/trainsn/VDL-Surrogate}.