Visual Concept Programming: A Visual Analytics Approach to Injecting Human Intelligence at Scale
Md Naimul Hoque, Wenbin He, Shekar Arvind Kumar, Liang Gou, Liu Ren
View presentation:2022-10-19T15:00:00ZGMT-0600Change your timezone on the schedule page
2022-10-19T15:00:00Z
Prerecorded Talk
The live footage of the talk, including the Q&A, can be viewed on the session page, Decision Making and Reasoning.
Fast forward
Abstract
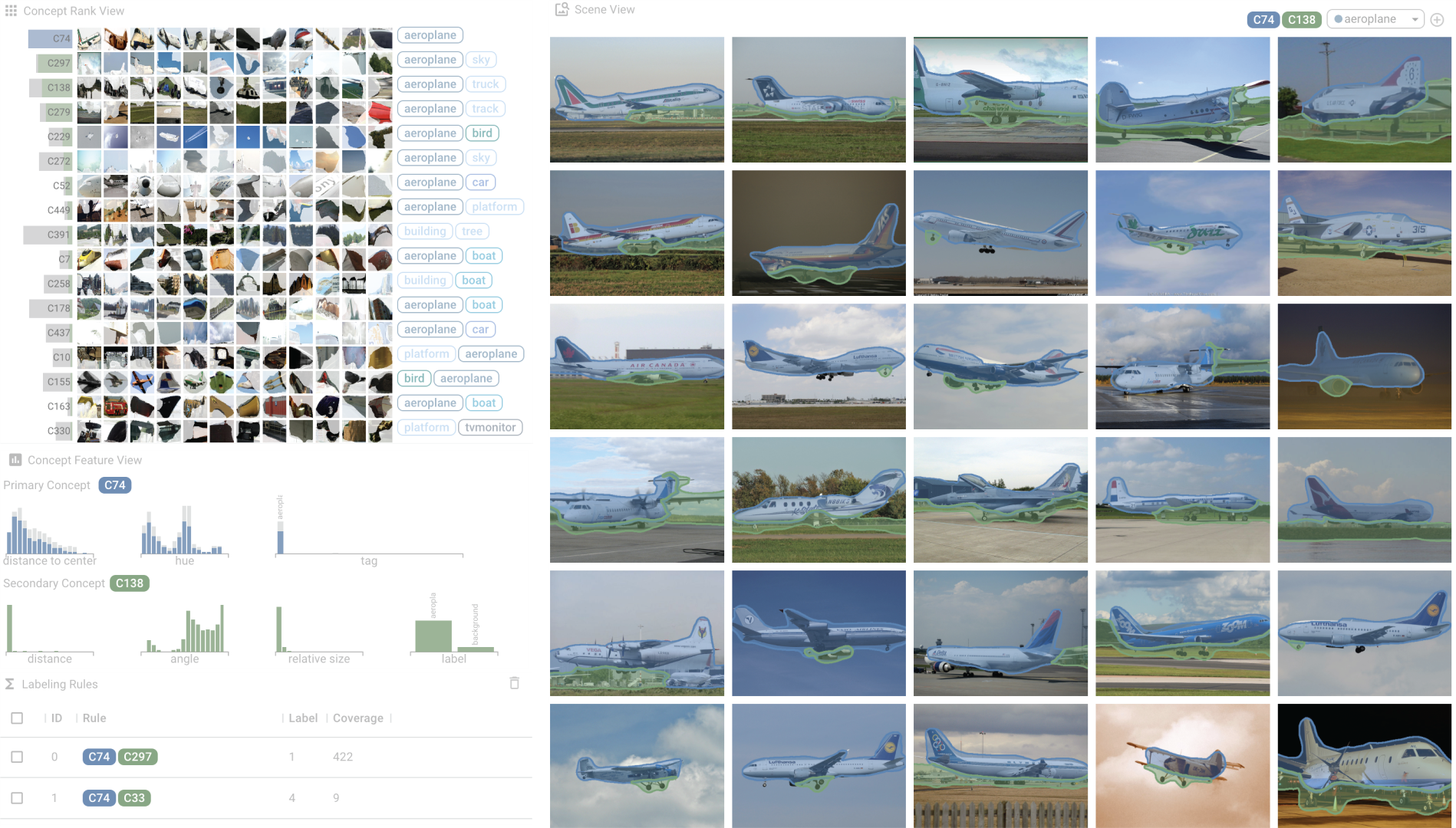
Data-centric AI has emerged as a new research area to systematically engineer the data to land AI models for real-world applications. As a core method for data-centric AI, data programming helps experts inject domain knowledge into data and label data at scale using carefully designed labeling functions (e.g., heuristic rules, logistics). Though data programming has shown great success in the NLP domain, it is challenging to program image data because of a) the challenge to describe images using visual vocabulary without human annotations and b) lacking efficient tools for data programming of images. We present Visual Concept Programming, a first-of-its-kind visual analytics approach of using visual concepts to program image data at scale while requiring a few human efforts. Our approach is built upon three unique components. It first uses a self-supervised learning approach to learn visual representation at the pixel level and extract a dictionary of visual concepts from images without using any human annotations. The visual concepts serve as building blocks of labeling functions for experts to inject their domain knowledge. We then design interactive visualizations to explore and understand visual concepts and compose labeling functions with concepts without writing code. Finally, with the composed labeling functions, users can label the image data at scale and use the labeled data to refine the pixel-wise visual representation and concept quality. We evaluate the learned pixel-wise visual representation for the downstream task of semantic segmentation to show the effectiveness and usefulness of our approach. In addition, we demonstrate how our approach tackles real-world problems of image retrieval for autonomous driving.