OSCAR: A Semantic-based Data Binning Approach
Vidya Setlur, Michael Correll, Sarah Battersby
View presentation:2022-10-20T14:27:00ZGMT-0600Change your timezone on the schedule page
2022-10-20T14:27:00Z
Prerecorded Talk
The live footage of the talk, including the Q&A, can be viewed on the session page, Personal Visualization, Theory, Evaluation, and eXtended Reality.
Fast forward
Keywords
Data-driven semantics, binning, constraints, geospatial
Abstract
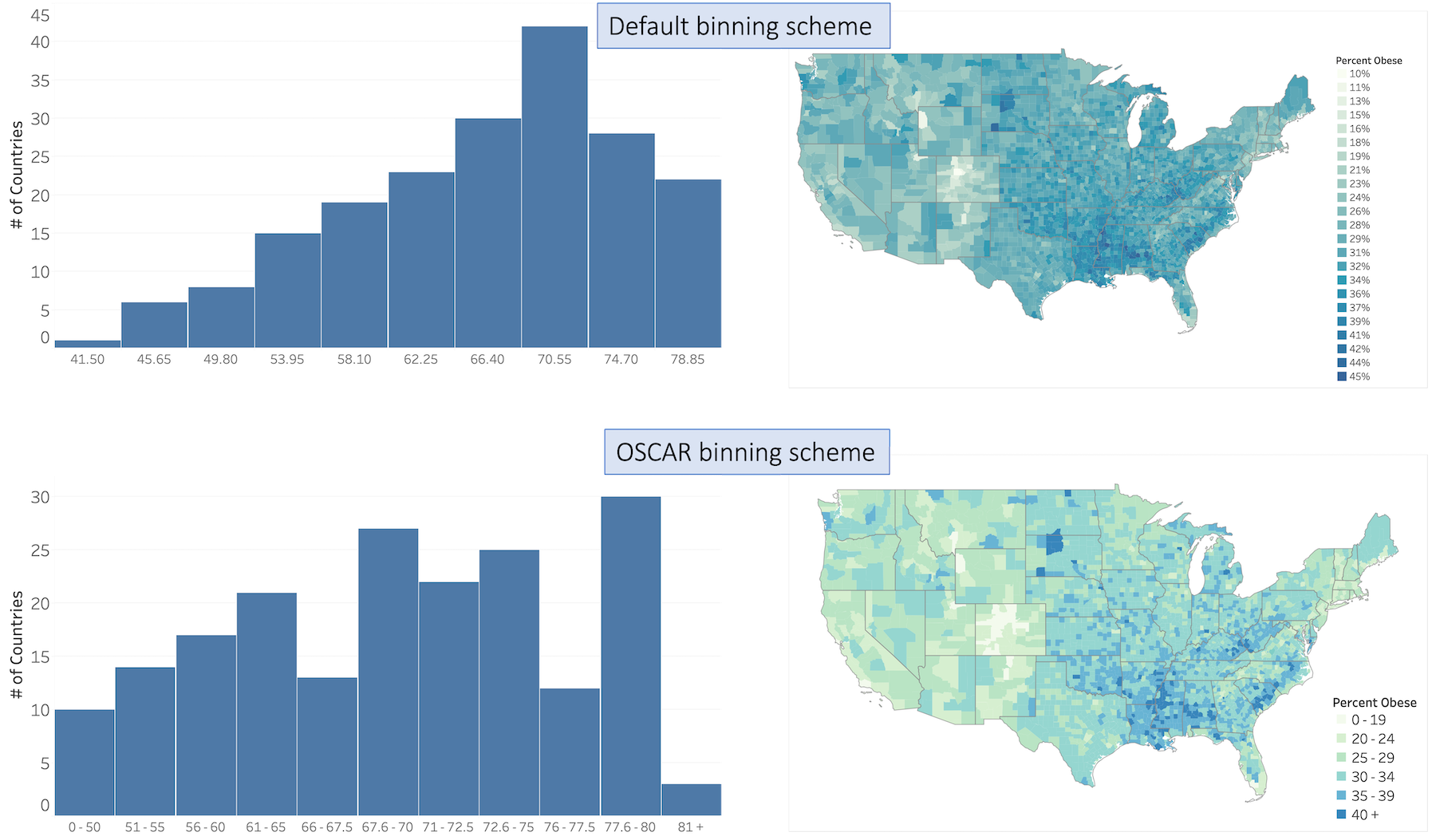
Binning is applied to categorize data values or to see distributions of data. Existing binning algorithms often rely on statistical properties of data. However, there are semantic considerations for selecting appropriate binning schemes. Surveys, for instance, gather respondent data for demographic-related questions such as age, salary, number of employees, etc., that are bucketed into defined semantic categories. In this paper, we leverage common semantic categories from survey data and Tableau Public visualizations to identify a set of semantic binning categories. We employ these semantic binning categories in OSCAR: a method for automatically selecting bins based on the inferred semantic type of the field. We conducted a crowdsourced study with 120 participants to better understand user preferences for bins generated by OSCAR vs. binning provided in Tableau. We find that maps and histograms using binned values generated by OSCAR are preferred by users as compared to binning schemes based purely on the statistical properties of the data.