Using Large Language Models to Generate Engaging Captions for Data Visualizations
Ashley Liew, Klaus Mueller
View presentation:2022-10-16T20:03:00ZGMT-0600Change your timezone on the schedule page
2022-10-16T20:03:00Z
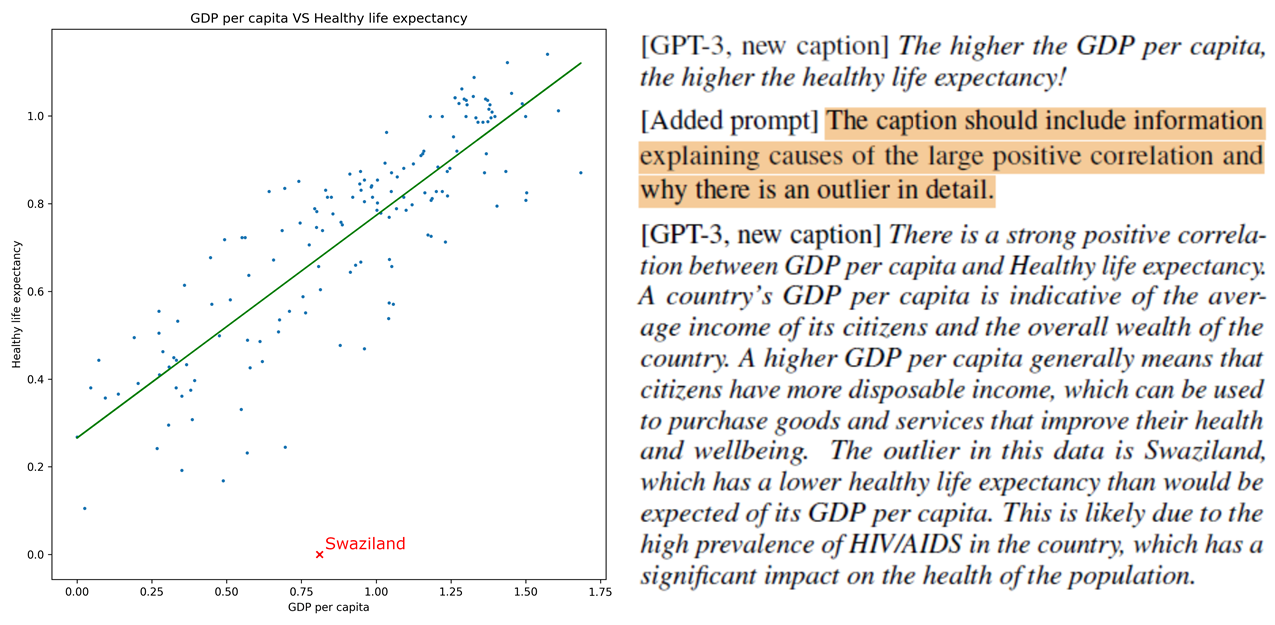
The live footage of the talk, including the Q&A, can be viewed on the session page, NLVIZ: Opening, Keynote and Paper Session I.